
NVIDIA
Trimble used NVIDIA Isaac Sim to train the Spot robot for autonomous data collection.
Get news, papers, media and research delivered. Sign up for our free newsletters.
Stay up-to-date with news and resources you need to do your job. Research industry trends, compare companies and get weekly market intelligence with Robotics 24/7.

NVIDIA
Trimble used NVIDIA Isaac Sim to train the Spot robot for autonomous data collection.
Deploying an autonomous robot to a new environment can be a tough proposition. How can you gain confidence that the robot’s perception capabilities are robust enough so it performs safely and as planned? Trimble faced this challenge when it started building plans to deploy the Spot robot in a variety of indoor settings and construction environments.
Sunnyvale, Calif.-based Trimble needed to tune the machine learning (ML) models to the exact indoor environments so Boston Dynamics' quadruped could autonomously operate in these different indoor settings.
“As we deploy Spot equipped with our data-collection sensors and field-control software to indoor environments, we need to develop a cost effective and reliable workflow to train our ML-based perception models,” said Aviad Almagor, division vice president of emerging technology at Trimble.
“At the heart of this strategy is an ability to analyze synthetic environments," he said. "Using NVIDIA Isaac Sim on Omniverse, we could seamlessly import different environments from CAD tools like Trimble SketchUp. Generating perfectly labeled ground-truth synthetic data then becomes a straightforward exercise.”
To ensure that models work robustly, developers working on robotics and automation applications need diverse datasets that include all assets of the target environment. In case of indoors, the list might include assets such as partitions, staircases, doors, windows, and furniture.
While these datasets can be constructed manually with real photographers and human labelers, that approach requires much preplanning and high costs and often gates when your project can start. With synthetic data, you can bootstrap your ML training and get started immediately.
When building this dataset, you could choose to include segmentation data, depth data, or bounding boxes. This perfectly labeled ground truth data can open many doors of exploration. Some things like 3D bounding boxes can be easily obtained synthetically while they are notoriously difficult to label by hand.
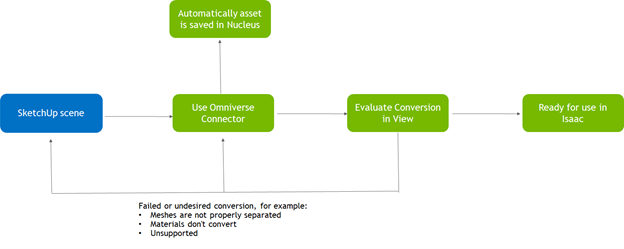
Let's take a look at the steps taken to build a training workflow using synthetic data generated from simulation. Although this workflow includes sophisticated simulation and ML technology, the steps required to complete this project are simple:
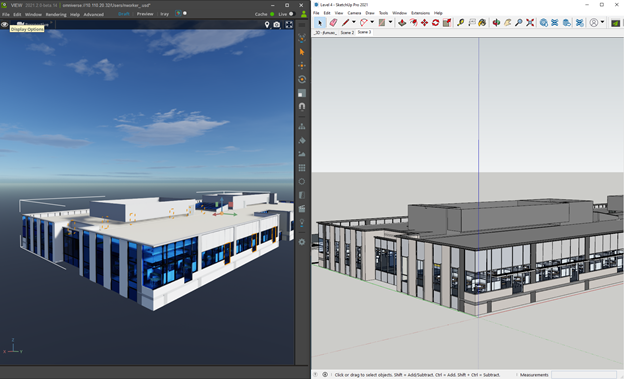
In this project, the environment was available in Trimble SketchUp, a 3D modeling application for designing buildings. To import assets, NVIDIA Omniverse supports the USD format for scene description. The SketchUp model is converted to USD and imported using one of the Omniverse Connectors.
To ensure that all the assets are properly imported, you must inspect the environment using NVIDIA Isaac Sim or the Create or View apps in Omniverse. In some cases, this process may require a few iterations until the environment is satisfactorily represented in Omniverse.
Synthetic data is an important tool in training ML models for computer vision applications, but collecting and labeling real data can be time-consuming and cost-prohibitive. Moreover, collecting real training data for corner cases can be sometimes tricky or even impossible.
For example, imagine training an autonomous vehicle to recognize and react properly to ensure safety of pedestrians crossing a busy street. It would be reckless and dangerous to set up a photoshoot in a crosswalk with live traffic.
As Trimble planned to deploy autonomous mobile robots in different environments for different use cases, it faced a training data dilemma: How to safely get the right training datasets for these models in a reasonable timeframe and at a reasonable cost?
The built-in synthetic data generation capabilities of NVIDIA Isaac Sim directly address this challenge.
A key requirement for generating synthetic datasets is support of the right set of sensors for the ML models that are being deployed. As noted in the later example, NVIDIA Isaac Sim supports rendering images with bounding boxes, depth, and segmentation, which are all important for helping a robot perceive its surroundings.
Additional sensors like lidar and ultrasonic sensors (USS) are also supported in NVIDIA Isaac Sim and can be useful in some robotic applications.
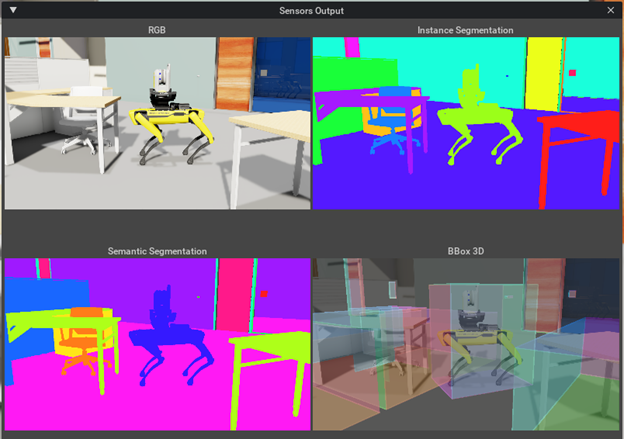
The other superpower of generating synthetic data is domain randomization. Domain randomization varies the parameters that define a simulated scene, such as the lighting, color, and texture of materials in the scene.
One of the main objectives is to enhance ML model training by exposing the neural network to a wide variety of domain parameters in simulation. This helps the model to generalize well when it encounters real world scenarios. In effect, this technique helps teach models what to ignore.
Randomizable parameters in NVIDIA Isaac Sim:
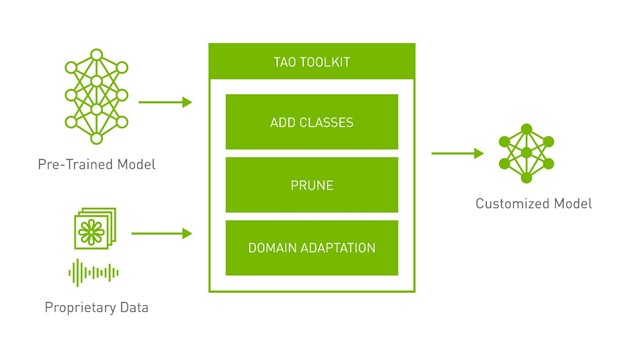
Below are pretrained models and proprietary data (real or synthetic) as inputs and a customized model as the output.
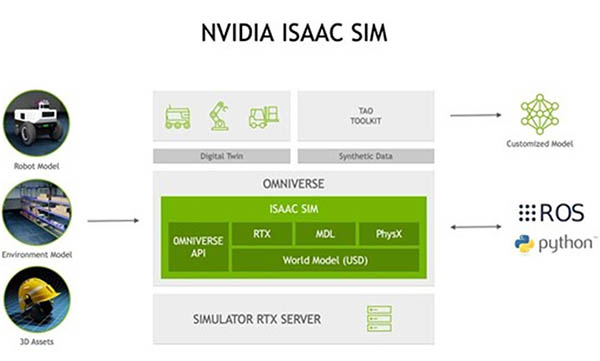
The image below shows that the simulator can be controlled from both ROS and Python. The outputs of the simulator include the digital twin and synthetic data, which can be used to train perception models.
After the datasets are generated, formatting them properly to work with the NVIDIA TAO Toolkit enables you to greatly reduce the amount of time and expense of training the models while ensuring that the models are accurate and performant. The toolkit supports segmentation, classification, and object detection models.
The datasets that are synthetically generated in NVIDIA Isaac Sim are output in the KITTI format to be used seamlessly with the TAO toolkit. For more information about outputting data in NVIDIA Isaac Sim for training, see Offline Training with TLT.
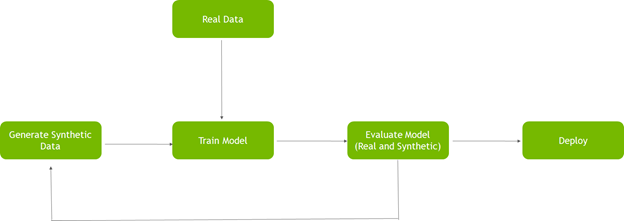
When working with synthetic datasets compared to real data, you may want to iterate the dataset to get better results. The chart below shows this iterative process of training with synthetic datasets.
Trimble faced an all-too-common challenge of getting training data for its ML models for an autonomous robot in a cost-effective workflow. The solution to this challenge was to leverage the power of the connectors in NVIDIA Omniverse to import CAD data into USD efficiently. The data could then be brought into NVIDIA Isaac Sim.
In the simulator, the powerful synthetic data capabilities of Isaac Sim make generating the required datasets straightforward. You can provide synthetic data to enable a more efficient training workflow and safer autonomous robot operation.

Nyla Worker is a solutions architect at NVIDIA focused on simulation and deep learning within embedded devices. She has extensive experience working on deep-learning edge applications for robotics and autonomous vehicles, as well as developing accelerated inference pipelines for embedded devices.

Gerard Andrews is a senior product marketing manager at NVIDIA focused on the robotics developer community. Prior to joining NVIDIA, he was product marketing director at Cadence, responsible for product planning, marketing, and business development for licensable processor IP. Andrews has an MS in electrical engineering from Georgia Institute of Technology and a BS in electrical engineering from Southern Methodist University.
This NVIDIA developer blog is reposted with permission.
This video presents different ways to rely on digital twins to carry out an autonomous machines at a robotics systems. This talk explains how simulation has played a key role in different stages of development of the legged robot autonomous navigation.

From geometry preparation to AI-assisted analysis, integrated CFD workflows…

Software-based GripperAI manages mixed picking through basic geometry

Safety, communication and motion control components enable smooth operation

North America’s largest robotics and automation event winds down